
Small system, big system: Scaling read database
Scaling relational read that you can use to tackle a lot of system design problems

Welcome to the small system, large system video series, where I deep dive into a small system, so that you can reuse it to build a large system.
If you prefer a video version, here it's
Almost every system will read some data from databases. So let's look at a very common way to scale a relational database read step by step. By remembering this approach, you could apply it to most of your backend system design interviews.
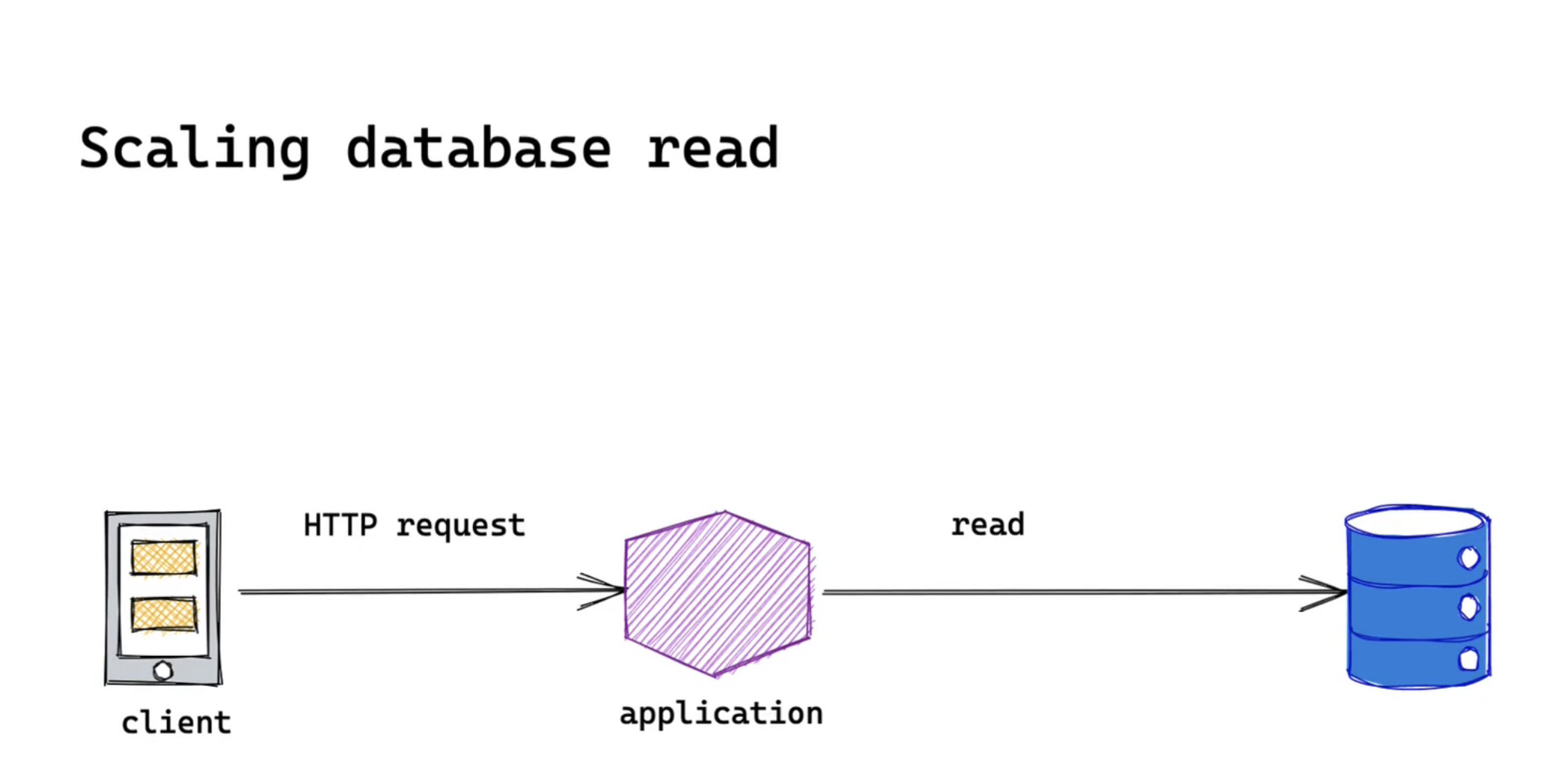
Here we have a system composed of a client, a server and a database to persist data. We will mainly focus on the database read. We'll do this iteratively. This means we'll start from one single instance relational database. As our database read requests become higher we'll see how we can improve the read scalability while considering the trade-off.
Scaling up
First of all, we should always mention scaling up vertically. Scaling up vertically means adding more resources to your database instance. However, this approach will hit its capacity limits as it is capped by the hardware resources. For example, the largest memory-optimized instances of Amazon RDS(at this moment) is db.r5b.24xlarge
Read replicas
This is when we want to introduce read replicas.
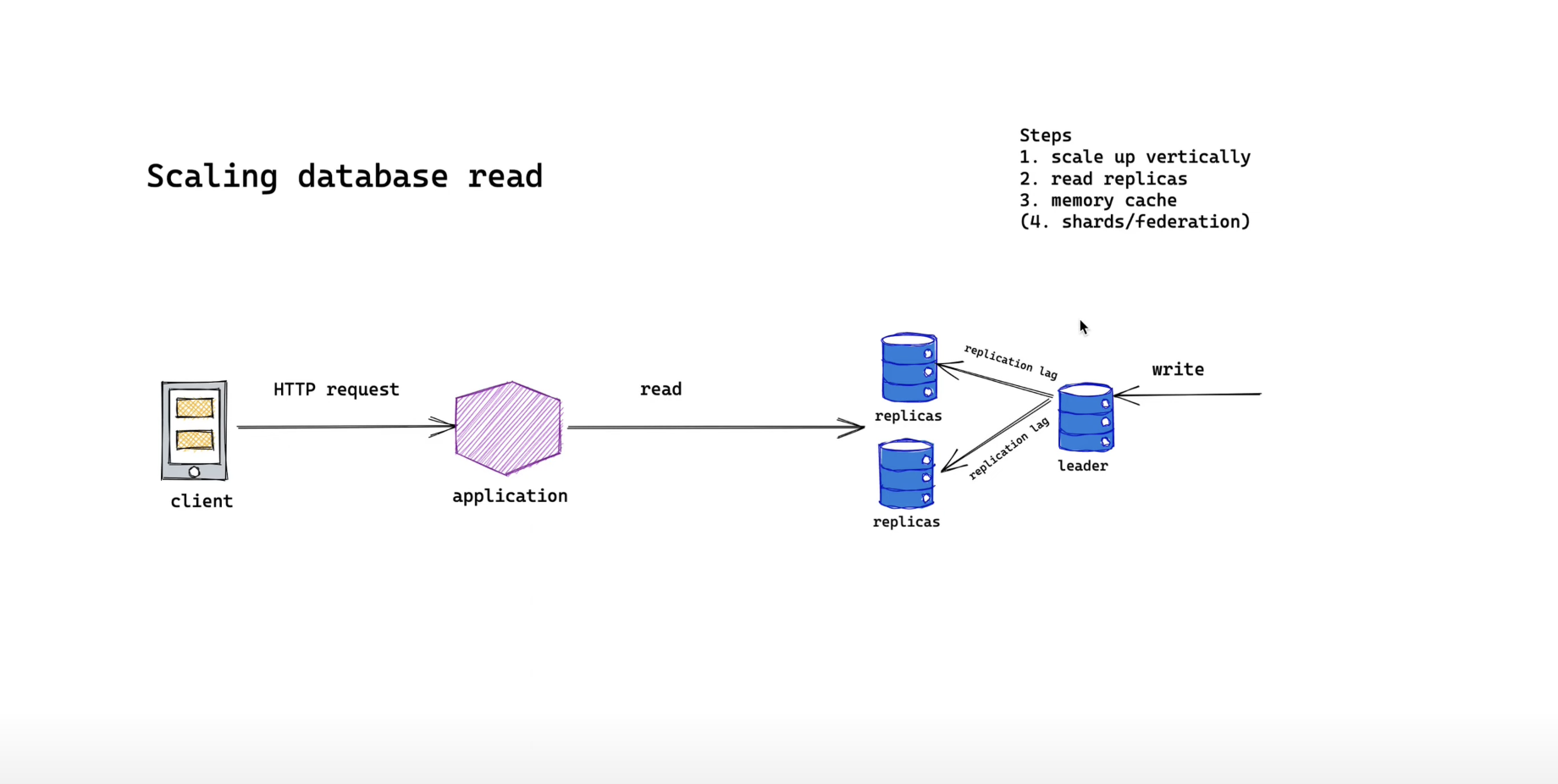
Adding more read replicas, our database is now more capable of accepting more read requests. Also, since we separate our write and read instances, it increases our system reliability.
If our write instance is unhealthy, we can still serve our read requests through our replicas.
However, our application server now has to figure out which replica we have to read from since we have more than one replica. And we want to make sure the read requests are distributed evenly across our instances
The biggest challenge though is replication lags, which means we might not get the latest data before replication between leader and replicas are completed. So users might see outdated data like older profile pictures. However, in most cases, we are willing to sacrifice this kind of inconsistency with scalability
Replicas, they are nice. But it doesn't mean they are indefinite. Relational databases have group limit on the number of replicas you can set. So as our read request becomes higher and higher we are going to hit our replicas group limit.
Memory cache
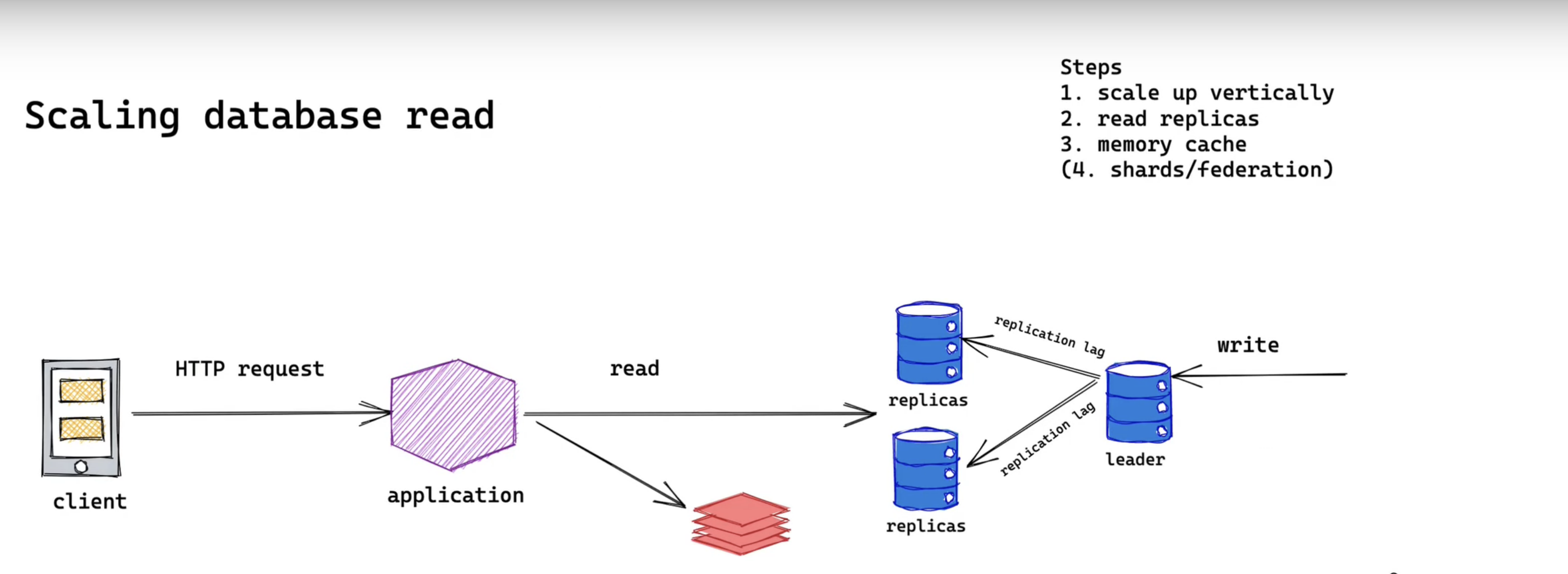
Right now we will add a memory cache layer in front of database. If the data we want to read is in the cache we could avoid hitting database directly. Also, since memory is faster than disk. So it will decrease our system overall response time. It will also be beneficial to show your interviewer that you know the common latency.
However, similar to the replication lag we have to deal with data inconsistency. And since memory is not cheap we have to plan our memory capacity accordingly. If there's a number you can always do a quick calculation during your interview.
Let's say you want to store a list of user id in our memory cache We use integer type which will take 4 bytes of our storage and let's say our daily active user is 10 million
4 bytes * 10 million = 40 Mbytes
And we'll need 40 megabytes for memory cache which is a reasonable size. So I think we are good to go.
If you have time you could also mention about cache strategy that you will use. One common strategy is cache aside pattern or lazy loading. Most of the time, adding a cache layer with enough consideration should be more than enough.
Federation
If your interviewer doesn't stop we could talk about federation and sharding strategy Let's talk about federation. Usually, federation means splitting your entity into different databases.
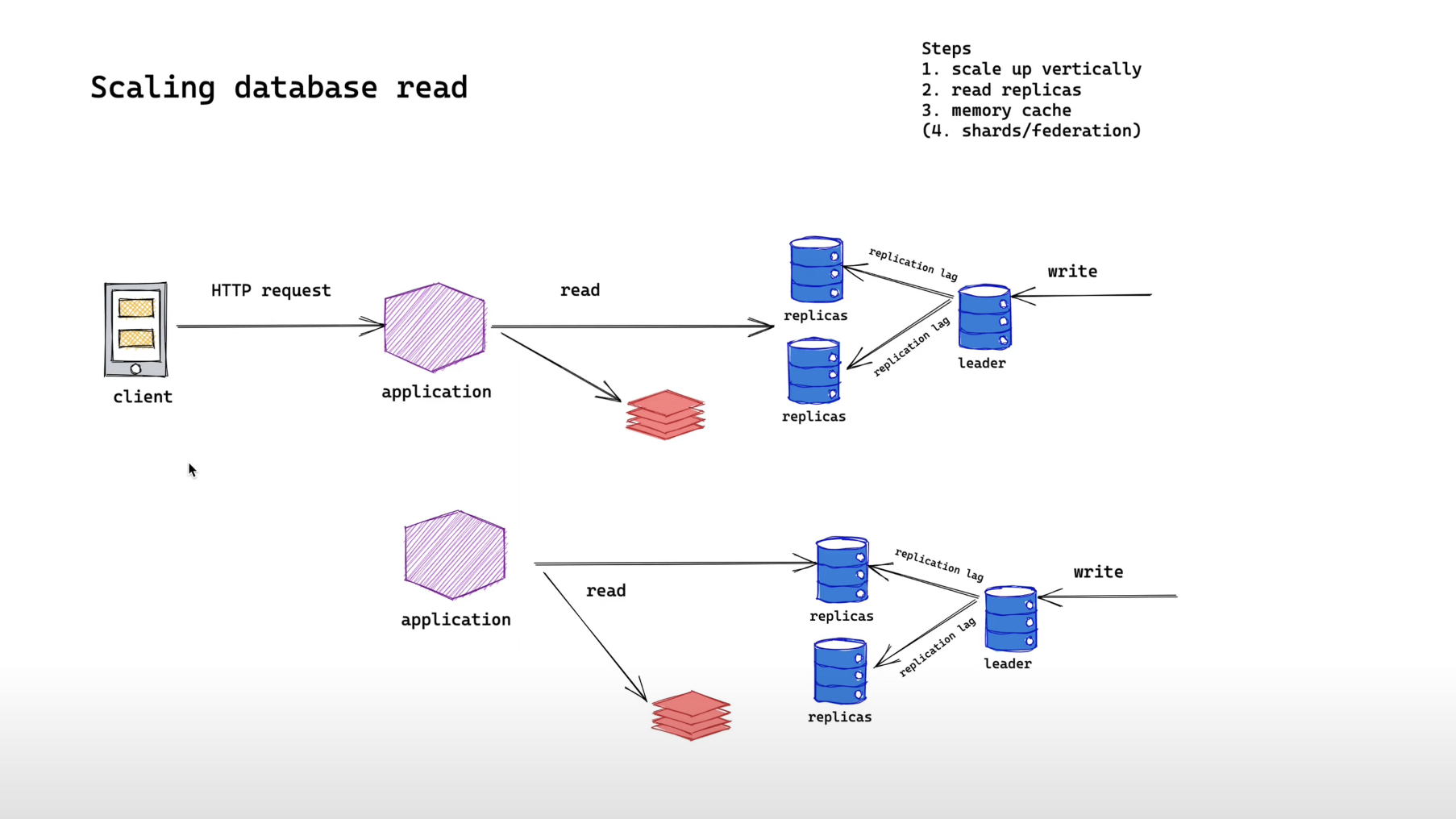
By introducing another cluster of databases we are now capable to scale more read requests. However, we might lose all the benefits that a relational database provides like the ability to join while we are creating it. Also, we might have to deal with transactions across databases
Summary
So I have walked you through a few steps to scale database read as our request increases.
If you are looking for system design interview like this, you should check out systemdesign.gaijineer.co




