
Small system, big system: Metrics aggregration

Let's talk about some aggregation strategies you can use when you are asked to design Google Analytics like services. This is a huge topic but we will focus on how do we collect data so that we could provide a reporting system to users. We will discuss how do we aggregate the data from logs into metrics, with a goal to answer these two questions from two very different types of users. Firstly, application user who is interested in their own domain and secondly internal analyst who wants to understand data through a bigger picture to drive business decision
- (application user use case) What is this domain total impression last hour?
- (internal analyst use case) What is the total revenue by all customers for the last quarter?
We are going to talk about:
- How do we collect data
- Where do we store the collected data aka centralized system of records
- How do we aggregate our collected data to answer questions
If you prefer video, here you go:
High Level Design
Before we start let's start with a very naive approach to understanding our data flow from a high level. The naive approach looks like this
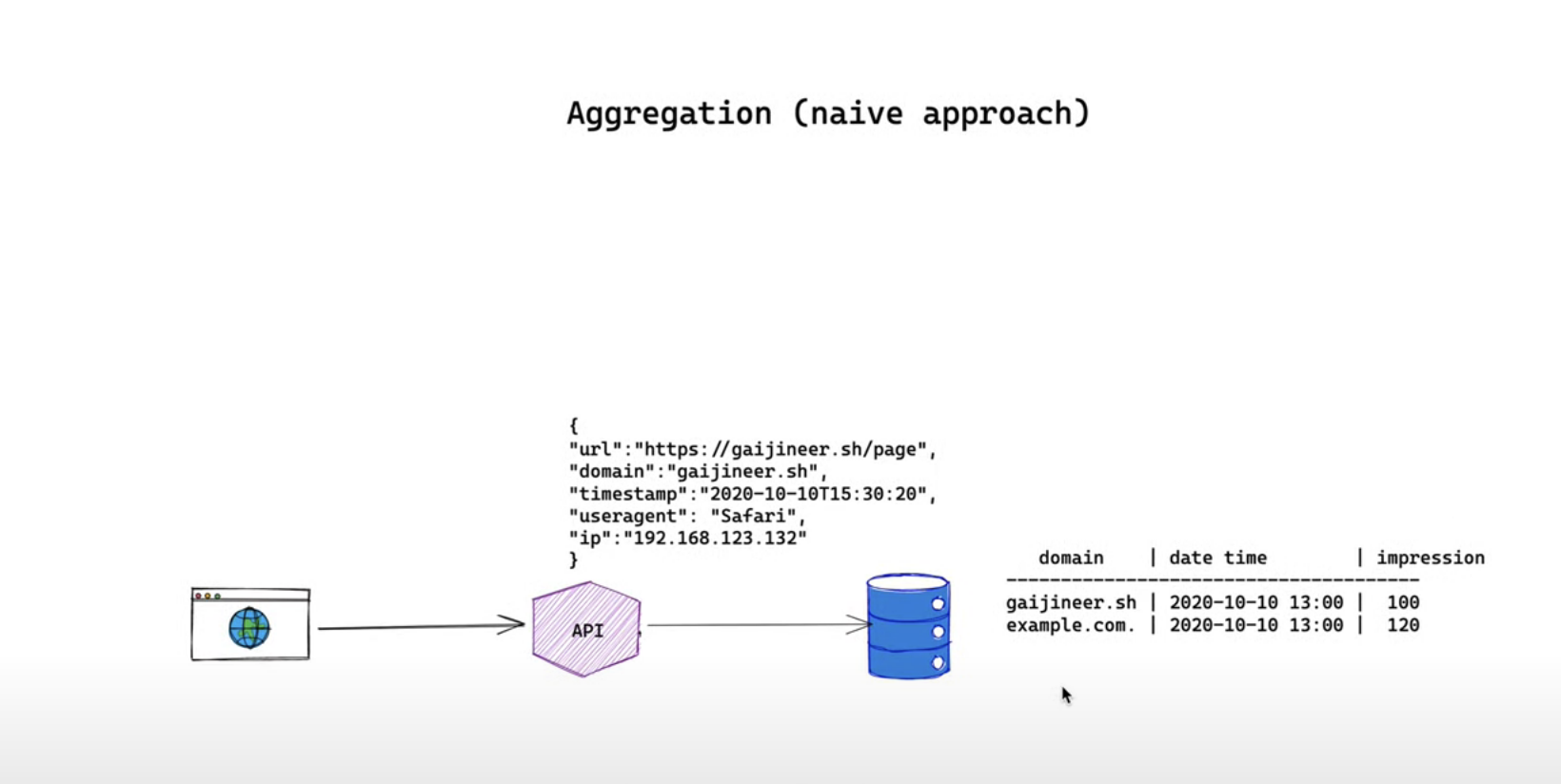
We have an API server that's ready to accept HTTP requests from the internet. How the requests are generated is not within the scope of this discussion they might come from our own javascript tag or public API. Once we get the request we parse the request and store them into our database to provide metrics for every domain in time series we design our database table to have domain and date time as a primary keys
This approach works and could answer our questions definitely. However, they are not flexible reliable and scalable as in
- what if you want to understand the total impression for the last 30 minutes
- what if our database has an outage during the insertion of data
- is our database able to store data over 10 years 20 years for our business needs
We'll look at how we address these problems step by step
Detailed steps
1. How do we collect data
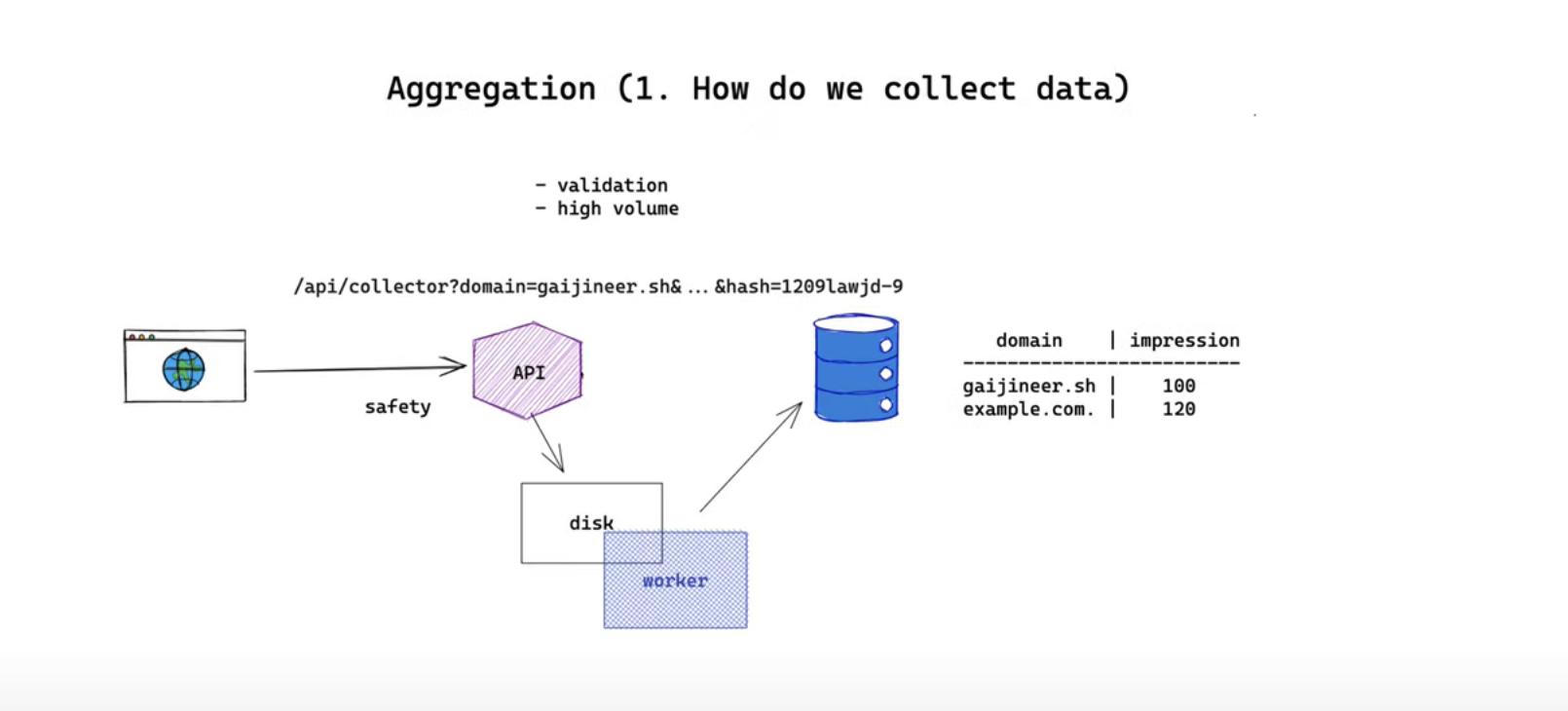
This is usually solved by exposing an HTTP endpoint. Since it is a public HTTP endpoint it means everyone from the internet is able to hit the endpoint from any source. We can have a token based authentication or if we are generating the URL dynamically we can append and encrypt the hash that contains information for our server to validate if the URL is generated by yourself. This endpoint is expected to have a high volume of traffic thus it should be responsive and fast.
The main job of this API server is to persist the log into a centralized system of record like a database which is probably through a TCP connection. Opening up a socket for every request to send data directly to the database will be time and resource-consuming. And because the database might go offline it is unreliable so it makes sense to persist the log to a local file system at first. The logging library we choose should be able to write some logs to memory and bulk append them to a disk at a later point for performance reasons. We need a background worker to send those requests to our centralized system of record at a later point periodically. One downside with this approach is we might need a bigger disk for our API server and if the disk fills up we need a mechanism to rotate them.
2. Centralized system of records
Where do we install the collected data aka centralized system of records? Our data are immutable log so most of the storage you are aware of should be able to store them fast enough since the operation is only appending. A few options we can have for our centralized system records are
- Database of your choice (Could be RDB, key-value, document-oriented)
- Distributed file system or object storage. Like S3
- Stream database A few worth considering points are durability, redundancy and single source of truth
Durability
We want our logs to be persisted one is written so we like our data to be stored on disk over memory. So no Redis (although Redis has a persistence option) or Memcached.
Redundancy
Even if it is persisted the hardware problem such as corrupted disk might lead to data loss. If the data is critical to our mission we want to reduce such risk. One way to increase redundancy is to copy data from another disk so that we could locate them on a different machine with the tradeoff of a higher cost.
Single source of truth
If anything happens at the post-processing stage there should always be one single source of truth to consume data from. This makes sure our data is consistent of course across the post-process results.
Hence I'd like to propose a solution that fulfils the above requirements: stream database. Everything new event goes into the stream and the stream will act as our single source of truth.
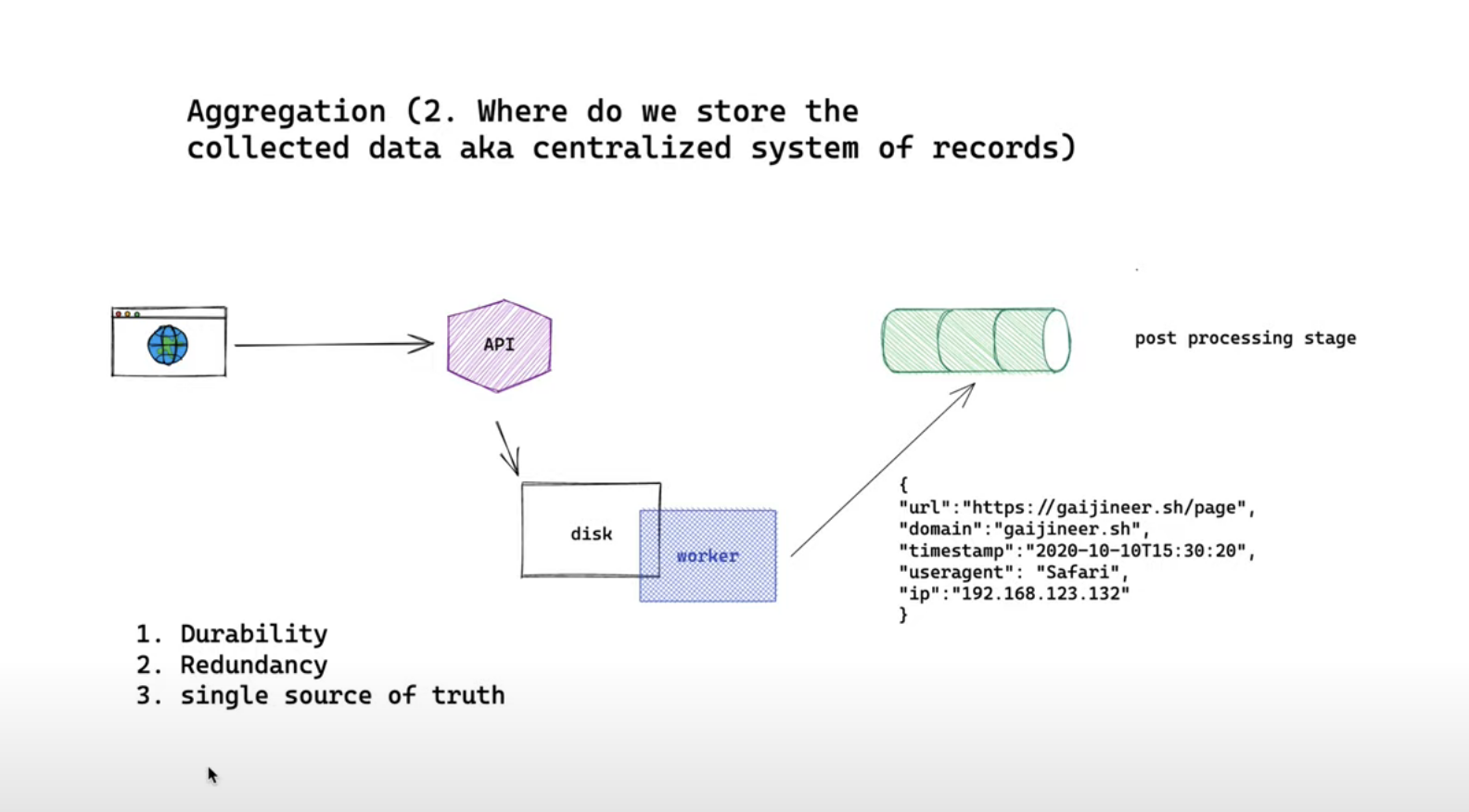
Choosing a stream database like Kafka will give us durability and we can replicate our data into a different cluster for redundancy one really great benefit of stream database that other systems do not have is it treats changes as events. Let's say if you want to reprocess data you can always process the data in the order that they were inserted.
3. How do we aggregate our raw data to answer questions
Let's revise the two questions that we need to answer again:
- What is this domain total impression last hour?
- What is the total impression by all domains for last week?
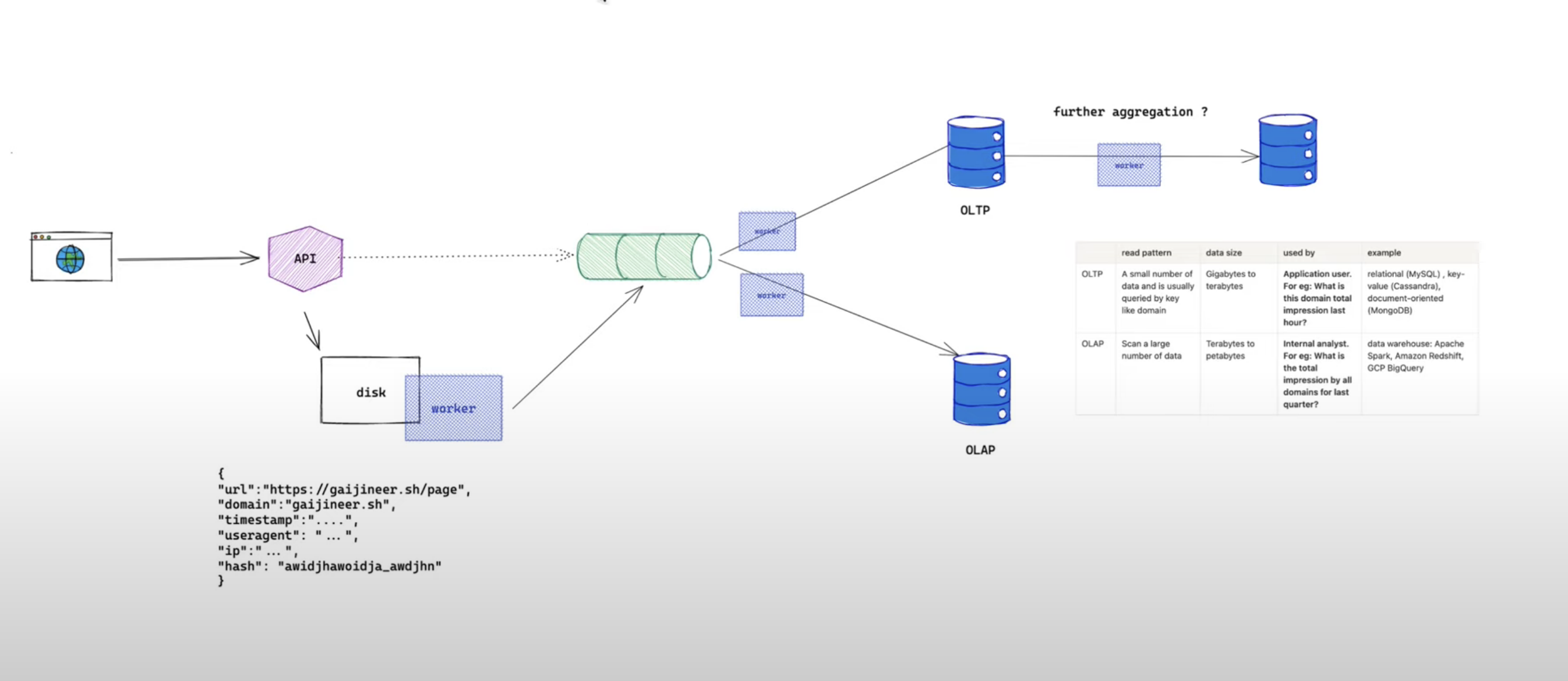
Depending on the questions, our solution may or may not be different, but let's discuss the 2 common approaches: online transaction processing (OLTP) vs online analytics processing (OLAP)
The difference between these two are shown in this table:
| read pattern | data size | used by | example | |
| OLTP | A small number of data and is usually queried by key like domain | Gigabytes to terabytes | Application user. For eg: What is this domain total impression last hour? | relational (MySQL) , key-value (Cassandra), document-oriented (MongoDB) |
| OLAP | Scan a large number of data | Terabytes to petabytes | Internal analyst. For eg: What is the total impression by all domains for last quarter? | data warehouse: Apache Spark, Amazon Redshift, GCP BigQuery |
Let's dig in a little bit into each question.
application user use case: What is this domain total impression last hour?
This question is typically asked by a domain owner, that's application user.
To answer this question, we are only interested in certain data, that's this domain data. Our query will usually come with a "WHERE domain =" clause. So, it's more efficient to index the domain key.
In this case, it makes sense to design our database table schema like this
Aggregation granularity
The date field is added to help us answer the "last hour" part in this question. If we are only interested in the last hour, it makes sense to group the data by the hour instead of smaller units like a minute, second or a larger unit like a week, month.
However, if we only aggregate our data per hour, the latest data we could see would be the aggregated past hour data. There is no way to see the last 15 minutes data. Needless to mention real-time data. If that is important to our business, we might want to know how many time lags we are allowed to.
Remember, the smaller the granularity (second, minute) we will have more flexibility to answer our question. But at the same time, we have to store more rows, hence taking up more space. So, it depends

It's also very common to do further aggregation depending on your business. We could have hourly, daily, monthly aggregation to answer different queries. For old data, hourly, daily become less valuable and hence we can remove those from our database when we are not interested in them anymore.
Anyway, if we do not have an idea of what is the best granularity, 15 minutes is a good start in my opinion for 2 reasons.
- 15 minutes is a good midpoint between flexibility and disk resources. For data like stock prices, it makes sense to consume the data in real-time but even on Yahoo Finance, 15 minutes delays are not uncommon
- Time zone agnostic. In case you don't know, while nearly all countries have hourly, half-hourly time zones, Nepal and Chatham Islands have a quarter-hourly time zone (Source: https://www.bbc.com/news/world-asia-33815153). This is strange but timezone has never been friendly to software engineers =( So to serve our data globally, it's smart to aggregate our data by quarter-hourly.
internal analyst use case: What is the total revenue by all customers for the last quarter?
Unlike application users, internal analysts might want to ask a more flexible question. For instance:
- Total impression by all customers from Europe
- Average impression by each browser (detected by User-Agent)
In this case, we usually want to be able to query raw data so no aggregation will provide better flexibility. If you are concerned about the huge disk resources we have to use you are totally right. So they tend to be slower compared to the application use case. In most cases, we are ok with this because compare to application users, we will have lesser internal analysts hence fewer queries. Furthermore, LDAP is optimized to aggregate many rows of data across multiple keys as most of them are column-oriented.
If you want to understand how column-oriented databases work from a high level, this article from the honeycomb is a very good read.
So, it depends
Any way you go, you don't want to use one solution for a different problem. Both questions that we asked could be answered by OLAP or OLTP alone but if an OLAP cluster is both used by internal analysts and application users, the application user would be affected if the internal analyst usage is overloaded.
Using different workers to subscribe to our single source of truth allows us to achieve answering these questions in scale.
And this will be the design we propose to answer both questions.
One concern you might have is what if our worker that is inserting data to OLAP/OLTP has some bug and we need to retry. Or how do we handle duplicated data in our stream database? It could happen if there is a bug in API, or when our write to disk fails to respond, but we actually wrote it, and we retry again. Anything can happen.
We don't want to double up impressions because it wasn't correct. And that leads us to idempotency.
idempotency
To be idempotent, we can add a unique hash when we persist the data to the local filesystem. This could be done by though our API server.
{"url":"https://gaijineer.sh/page", "domain":"gaijineer.sh", "timestamp":"2020-10-10T15:30:20", "useragent": "Safari", "ip":"192.168.123.132", "hash": "w_kdj0192ilj12d9a0h2081" }
By using this unique hash, we have a way to detect the duplication at a later stage. For example, during our OLAP query, we can use UNIQUE in our query to remove the duplication.
That's all for today!




